< 1. 상속관계 매핑 >
ORM에서 이야기하는 '상속 관계 매핑'은 객체의 '상속 구조'와. 데이터베이스의 '슈퍼타입, 서브타입' 관계를 매핑하는 것이다.
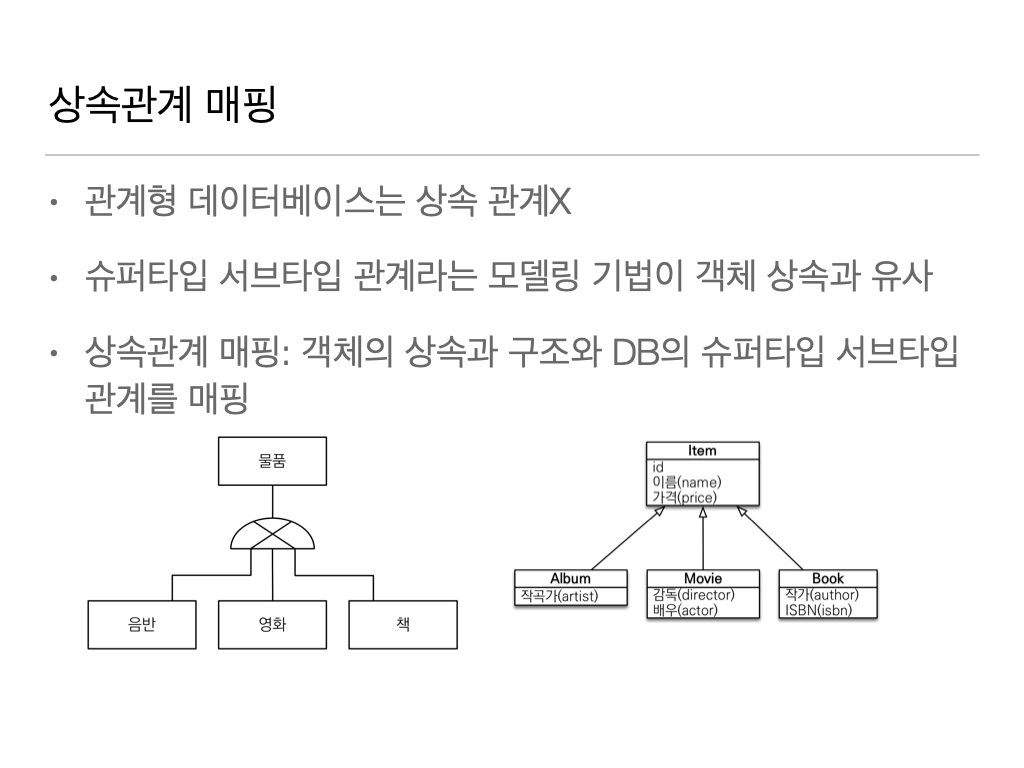
관계형 데이터베이스는 상속관계가 없다
- '슈퍼타입 서브타입 관계'라는 '모델링 기법'이 '객체 상속'과 유사
- 상속 관계 매핑 : 객체의 상속과 구조와 DB의 슈퍼타입, 서브타입 관계를 매핑
관계형 DB설계는 '논리모델'과 '물리모델'이 있다
'논리모델'은 공통적인 속성은 물품에 넣는다 - 슈퍼타입 서브타입
객체는 명확하게 상속관계가 있다.
상속관계 매핑
- 슈퍼타입 서브타입 논리모델을 '실제 물리 모델'로 구현하는 방법
1. 각각 테이블로 변환 -> JOIN 전략
2. 통합 테이블로 변환 -> 단일 테이블 전략
3. 서브타입 테이블로 변환 -> 구현 클래스마다 테이블 전략

-> 타입을 구분하는 '컬럼'을 추가해야 한다. 여기서는 DTYPE 컬럼을 '구분 컬럼'으로 사용
1. 조인 전략

-> Item이라는 테이블을 만들고 ALBUM, MOVIE,BOOK 테이블을 만든후 데이터를 나누고 JOIN 으로 구성하는것
-> INSERT는 두번을 하고 조회는 PK로 JOIN을 해서 가지고 온다. '구분하는 컬럼'을 따로 둔다
-> 데이터를 가장 정규화된 방식으로 JOIN. DB설계를 할 수 있다
장점
- '테이블 정규화'
- 외래 키 참조 '무결성 제약조건' 활용가능 -> ITEM_ID 를 사용가능
- 저장공간 효율화
단점
- 조회시 JOIN을 많이 사용, 성능 저하
- 조회 커리가 복잡함
- 데이터 저장시 INSERT SQL 2번 호출
--> JPA 표준 명세는 '구분 컬럼'을 사용하도록 하지만 '하이버네이트'를 포함한 몇몇 구분체는 '구분 컬럼(@DiscriminatorColumn)없이도 동작한다'
package hellojpa;
import javax.persistence.*;
@Entity
@Inheritance(strategy = InheritanceType.JOINED) // 조인전략의 테이블 설계 - 상속매핑은 부모 클래스에 선언해야 한다
@DiscriminatorColumn //DTYPE가 생긴다, DB에서 작업활때 어디에서 왔는지 확인하기 위해 필요하다
public abstract class Item {
@Id @GeneratedValue
@Column(name = "ITEM_ID")
private Long id;
private String name;
private int price;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getPrice() {
return price;
}
public void setPrice(int price) {
this.price = price;
}
}package hellojpa;
import javax.persistence.DiscriminatorValue;
import javax.persistence.Entity;
@Entity
@DiscriminatorValue("A") //엔티티를 저장할 때 '구분 컬럼'에 입력할 값을 저장한다
public class Album extends Item{
private String artist;
}package hellojpa;
import javax.persistence.DiscriminatorValue;
import javax.persistence.Entity;
@Entity
@DiscriminatorValue("B")
public class Book extends Item{
private String author;
private String isbn;
}
package hellojpa;
import javax.persistence.DiscriminatorValue;
import javax.persistence.Entity;
@Entity
@DiscriminatorValue("M")
@PrimaryKeyJoinColumn(name = "MOVIE_ID") //자식테이블의 '기본 키 컬럼명'을 변경(기본 값은 부모 테이블의 ID 컬럼명)
public class Movie extends Item{
private String director;
private String actor;
public String getDirector() {
return director;
}
public void setDirector(String director) {
this.director = director;
}
public String getActor() {
return actor;
}
public void setActor(String actor) {
this.actor = actor;
}
}
try {
Movie movie = new Movie();
movie.setDirector("aaaa");
movie.setActor("bbbb");
movie.setName("바람과 함께 사라지다");
movie.setPrice(10000);
em.persist(movie);
em.flush(); // 영속성 컨텍스트에 있는것을 DB에 날리고
em.clear(); // 영속성 컨텍스트를 깔끔하게 제거한다 - 1차캐시에 아무것도 남지 않는다.
Movie findMove = em.find(Movie.class, movie.getId()); //조회
System.out.println("findMove = " + findMove);
tx.commit();
} catch (Exception e) {
tx.rollback();
} finally {
em.close();
}
emf.close();
}
}2. 단일 테이블 전략
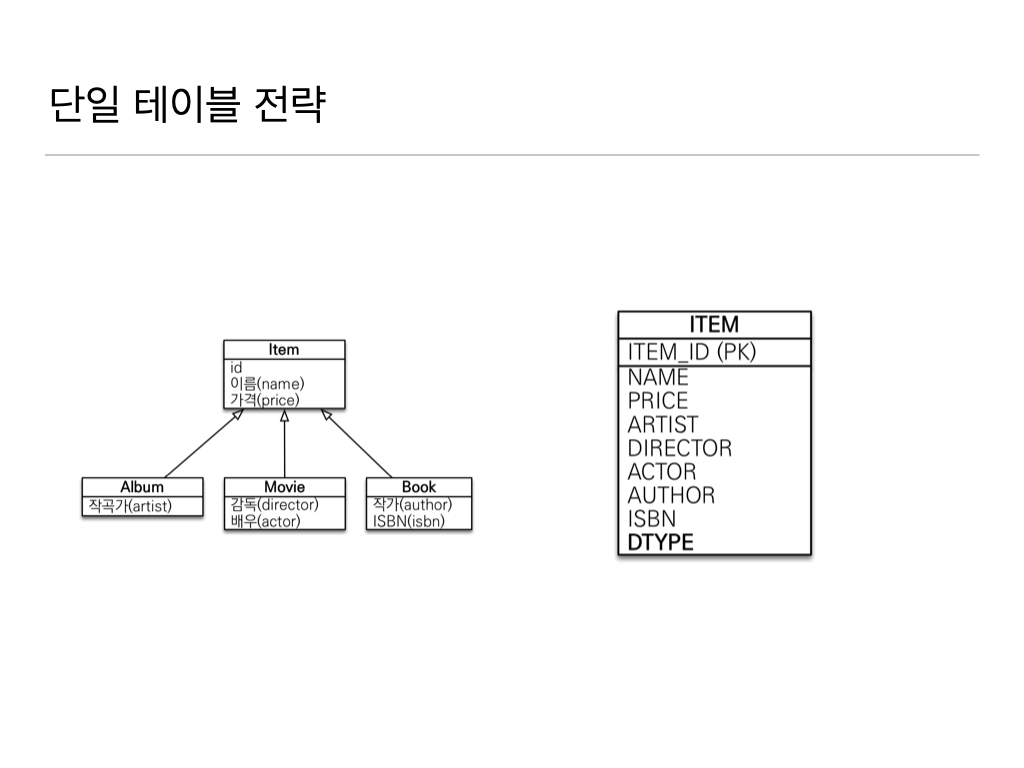
-> '논리모델'을 한 테이블로 합쳐버린다. 컬럼을 한 테이블에 다 때려박아버린다. DTYPE로 구분한다.
-> 성능이 가장 잘나온다.
-> INSERT도 잘나오고, 쿼리도 확인할 필요없다.
--> 주의점은 '자식 엔티티'가 매핑한 컬럼은 모두 null을 '허용'해야 한다.
package hellojpa;
import javax.persistence.*;
@Entity
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn //DTYPE가 생긴다, DB에서 작업활때 어디에서 왔는지 확인하기 위해 필요하다
public abstract class Item {장점
- JOIN이 필요없으므로 일반적으로 '조회 성능'이 빠름
- 조회 커리가 단순함
단점
- '자식 엔티티'가 매핑한 컬럼은 모두 null 허용 - name과 price빼고는 모두 허용해야 한다.
- '단일 테이블'에 모든 것을 저장하므로 테이블이 커질 수 있다. 상황에 따라서 '조회 성능'이 오히려 느려질 수 있다

-> ALBUM, MOVIE, BOOK 테이블만 만든후 각각 정보를 가지고 있는다.
package hellojpa;
import javax.persistence.*;
@Entity
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
@DiscriminatorColumn
public abstract class Item {-> "쓰면 안되는 전략"
< 2. @MappedSuperclass >
부모 클래스는 '테이블'과 매핑하지 않고 부모클래스를 상속받는 '자식 클래스'에게 '매핑 정보'만 제공하고 싶으면 @MappedSuperclass를 사용하면 된다. @MappedSuperclass는 '실제 테이블'과는 매핑되지 않는다. 이것은 단순히 매핑정보를 '상속'할 목적으로만 사용된다.

-> 객체입장에서 속성만 따로 사용하고 싶을 때 '공통 매핑 정보'가 필요할때 쓰는것
-> '상속관계 매핑'이 아니다
-> '엔티티'가 아니다, '테이블'과 매핑하지 않는다.
-> 부모 클래스를 상속받는 '자식클래스'에 '매핑정보'만 제공한다
-> 조회, 검색 불가(em.find(BaseEntity) 불가)
-> 직접 생성해서 사용할 일이 없으므로 '추상 클래스' 권장
@MappedSuperclass
public abstract class BaseEntity {
@Column(name = "INSERT_MEMBER")
private String createdBy;
private LocalDateTime createDate;
@Column(name = "UPDATE_MEMBER")
private String lastModifiedBy;
private LocalDateTime lastModifiedDate;@Entity
public class Member extends BaseEntity{@Entity
public class Team extends BaseEntity{-> '테이블'과 관계가 없고, 단순히 '엔티티'가 공통으로 사용하는 '매핑 정보'모으는 역할이다
-> 주로 등록일, 수정일, 등록자, 수정자 같은 '전체 엔티티'에서 '공통으로 적용하는 정보'를 모을때 사용한다
참고 : @Entity 클래스는 엔티티나 @MappedSuperclass로 지정한 클래스만 '상속'가능
-> 부모로부터 물려받은 '매핑 정보'를 재정의 하려면 @AttributeOverrides나 @AttributeOverride를 사용하고,
-> 연관관계를 재정의 하려면 @AssociationOverrides나 @AssociationOverride를 사용한다.